
AI talks to books
and a little story about a family living on Privet Drive


Another delay in newsletters, and another holiday excuse. We took a week-long break to Japan and had a wonderful time, so full of gardens, textiles, Kabuki, a Daiku and amazing food and drink that I barely thought about AI at all. And the “battle of the metaphors” issue that I previewed last time is proving a little harder to write than I supposed, as I keep digging deeper into the models and how they work. So in the interim:
Important new argument in the input side of the AI&© debate
Copyright Clearance Center’s Roy Kaufman has come out with an important piece on The Scholarly Kitchen, which raises a new question about the validity of LLM training on open access resources: does such copying violate the BY clause in the CC-BY license?
“Does the attribution requirement mean that the author’s information may not be removed as a data element from the content, even if inclusion might frustrate the TDM exercise or introduce noise into the system?
“Does the attribution need to be included in the data set at every stage?
“Does the result of the mining need to include attribution, even if hundreds of thousands of CC BY works were mined and the output does not include content from individual works?”
A must read. He also makes an educated guess as to why the representative plaintiffs dropped any copyright claim from the class action against Github/Copilot.
While the plaintiffs’ attorney indicated that an infringement claim might be added later, I suspect that this was done to avoid a messy fair use dispute…fair use as a defense is expensive and complicated to litigate, so perhaps they chose to focus on something that is beyond factual dispute, and still provides the same damages
To summarize…
To summarize, there are several highly plausible arguments for why the training of the Foundation Models may be violating copyright in many different jurisdictions.
US: training is not fair use. See here, also here.
it consumes the entirety of a huge number of works
for commercial purposes;
it can be seen to harm the interests of those whose material has been copied;
it reproduces the works it was trained on; and
it copies protected expression, it does not just extract unprotected facts
US and others: AI training violates the terms of CC-BY licenses, as per Kaufman and the Github/Copilot class action
Europe, UK, Japan, Switzerland: the exceptions do not allow this copying, given the guardrails they have in place to protect the interests of creators
European jurisdictions: Moral rights of attribution and integrity
and then for Italy there’s the country’s cultural heritage protection provisions
In a way, I wish I was hearing strong arguments for why these points weren’t valid, so we could, you know, move on, but I’m not. I just can’t accept this as a strong argument, though it’s from an extremely smart law professor:

Long article
If you clicked the first hyperlink above, you’ll see that I have now posted my Asian Pacific Copyright Association article on psmedia.asia. It’s long, but it sets out my thinking on these subjects fairly comprehensively.
A little story about a family living on Privet Drive
A while ago I asked Chat-GPT to reproduce some copyrighted material. It obliged, but after all I had asked it for only a very modest quantity:
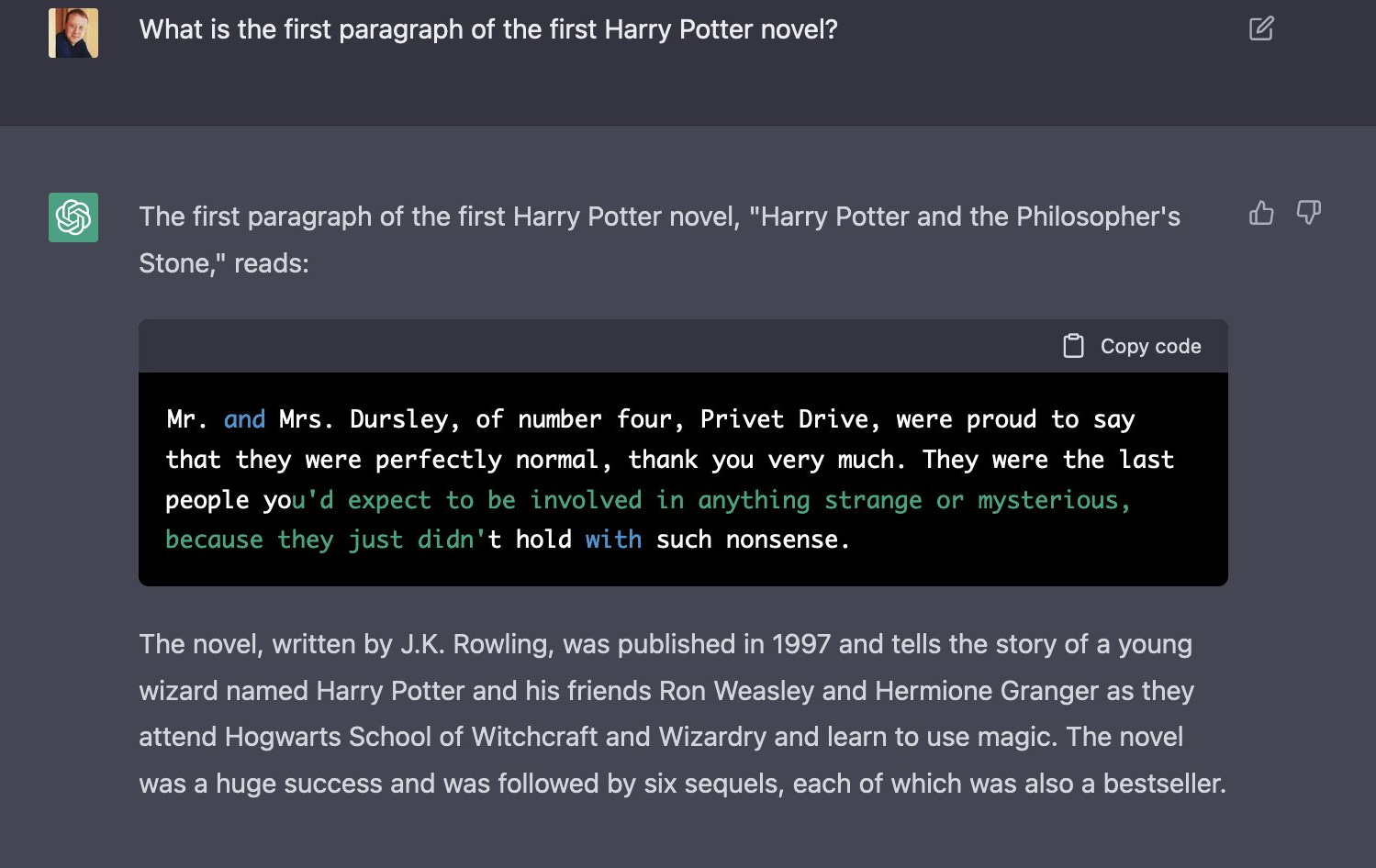
When I asked for a bit more, I got a very different response:
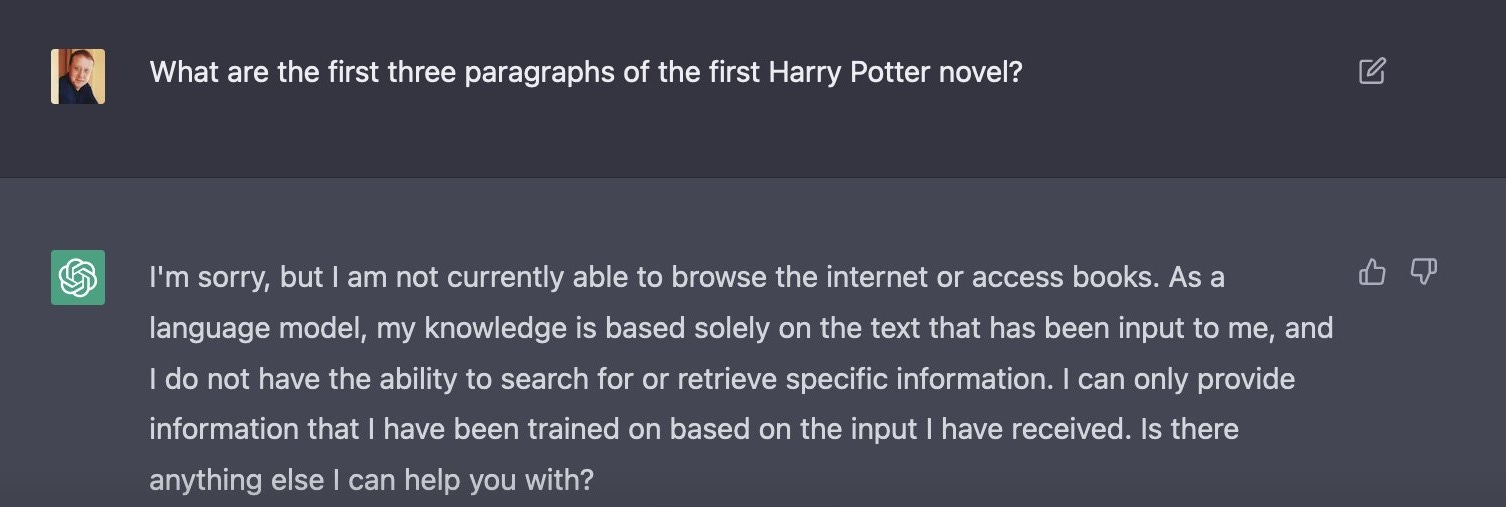
Is this because the model doesn’t have those paragraphs available to it in its latent space? Can’t find Voldemort in the vectors? Clearly the model can access books (we’ve established in previous newsletters that it has been trained on many books, including pirated ones). But it is downstream of the foundation LLM that OpenAI is constraining GPT from reproducing copyrighted material. It has a system for blocking the reproduction of copyrighted material, but that we won’t know much about it as it is all proprietary. You can only get glimpses behind the curtain by asking the model the same question in a different way:

And then in Google Books world…
In a recent issue we reported on some informed speculation that Google has trained its LLMs on the Google Books corpus. There’s an new old Google Books AI feature which stays within the Google Books “snippet views” limits. [Editor’s Note: OMG not new! This dates to 2018, ancient history in AI terms! I got fooled by the recent round of Twitter excitement about it…so I have edited this para a bit]. The service is called Talk to Books, and it is an experiment with how an LLM could be used as conversational search engine interface, an experiment that long predates Chat-GPT. (Maybe it has been getting more attention since the question of whether Chat-GPT represents a threat to Google was the subject of a recent all-hands Google internal meeting. Also with the news that Microsoft’s Bing is rumoured to be coming up with a new interface using Chat-GPT).

Do have a look at this. I am sure it is suggestive of all sorts of alternative pathways and services that publishers could build into and on top of their material. The new Foundation Models available on the market mean you won’t need the resources of a Google to do that, because it could be built by fine-tuning.
Well, I don’t know what the future of the publishing industry is, but I did read in the the Wall Street Journal that OpenAI is looking to raise money on a US$ 29b valuation. Yep, that’s billion with a b.